 异常教程
异常教程
数据太大:应对过度绘制
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
蒂姆布洛克。
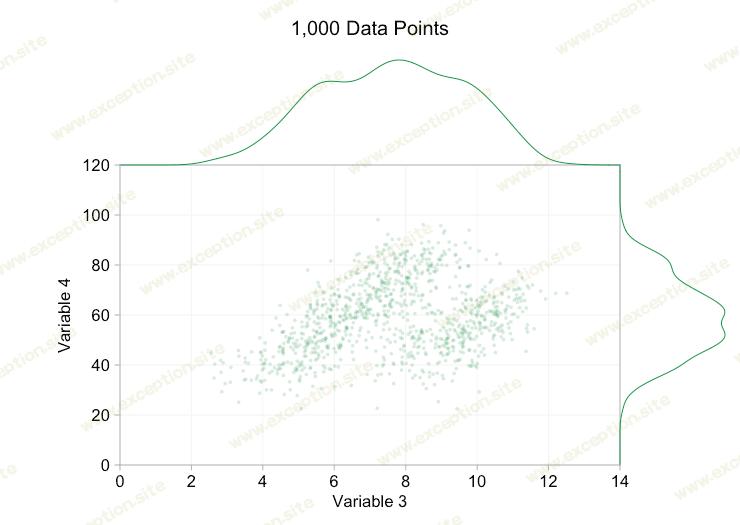
散点图是显示双变量数据中( 明显 )关系的好方法。您在表格中的大量数据中看不到的模式和集群可以在页面或屏幕上立即可见。随着近年来围绕大数据的所有炒作,人们很容易认为拥有更多数据始终是一种优势。但是随着我们向散点图中添加越来越多的数据点,我们可能会开始丢失这些模式和集群。这个问题是过度绘制的结果,在下面的动画中得到了演示。
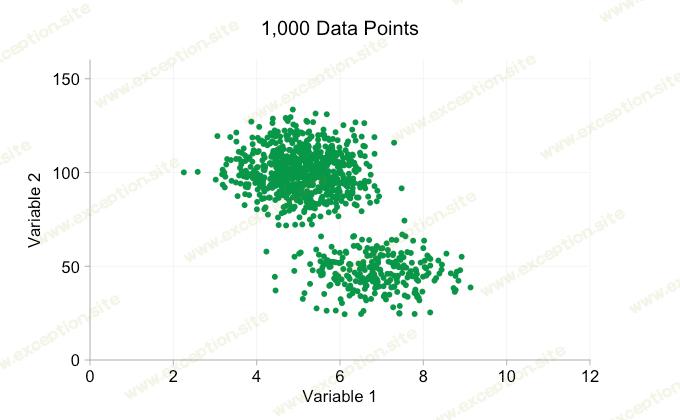
上面动画中的数据是从一对简单的双变量分布中随机生成的。随着我们添加越来越多的数据,这两种分布之间的区别变得越来越模糊。那么对于过度绘制我们能做些什么呢?
一种简单的选择是使数据点更小。 (请注意,如果许多数据点共享完全相同的值,这是一个糟糕的“解决方案”。)我们还可以使它们半透明。我们可以结合这两个选项:
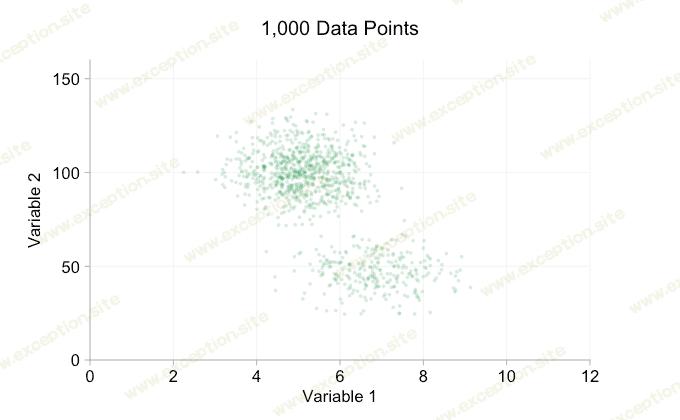
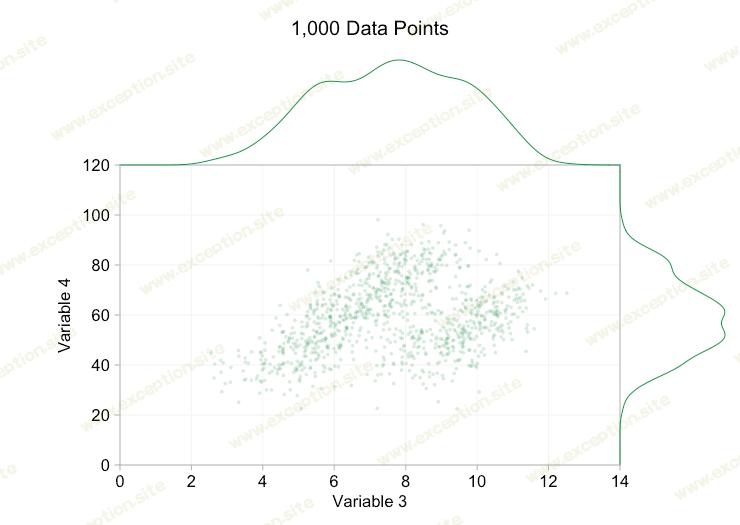
当我们拥有一万个数据点时,这些改进肯定会有所帮助。然而,当我们达到一百万点时,这两个分布似乎再次合并为一个。使点更小和更透明可能会有所帮助;尽管如此,在某些时候我们可能不得不考虑改变可视化。我们稍后再谈。但首先让我们尝试用一些额外的信息来补充我们的可视化。具体来说,让我们可视 化边缘分布 。我们有几种选择。 地毯图 的数据太多了,但我们可以对数据进行分类并显示 直方图 。或者我们可以使用更平滑的选项 - 核密度图 。最后,我们可以使用 经验累积分布 。最后一个选项避免了任何合并或平滑,但结果可能不太直观。我将在这里使用内核密度选项,但您可能更喜欢直方图。下面的动画 gif 与上面的 gif 相同,但添加了平滑的边缘分布。为了避免混乱,我保留了比例,因为我们只对相对高度的粗略判断感兴趣。
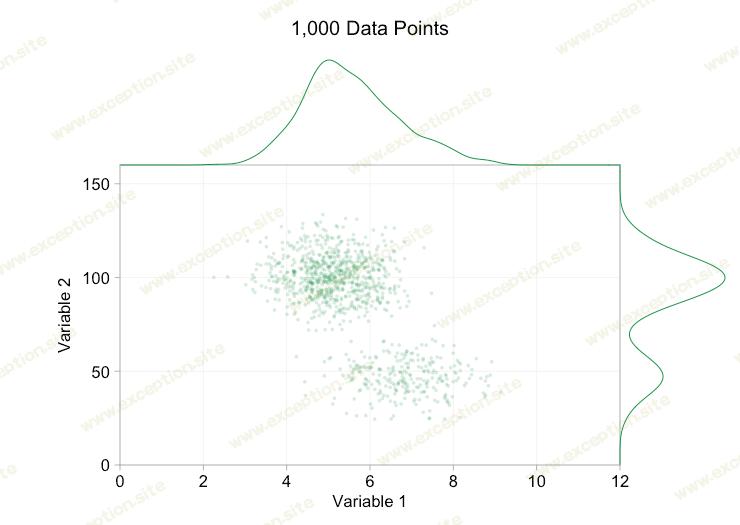
添加边际分布,尤其是变量 2 的分布,有助于阐明双变量数据中存在两种不同的分布。无论是一千个数据点还是一百万个数据点,变量 2 的双峰性质都很明显。这两个组件的相对大小也很清楚。相比之下,尽管来自两个不同的分布,但变量 1 的边际分布只有一个峰值。这应该清楚地表明,添加边际分布绝不是散点图中过度绘制的通用解决方案。为了强调这一点,下面的动画在具有边缘分布的散点图中显示了一组完全不同的(生成的)数据点。数据再次来自两个不同二维分布的随机样本,但完整数据集的两个边缘分布都未能突出这种分离。和以前一样,当数据点的数量很大时,也无法从散点图中看出两个集群之间的区别。
回到点大小和不透明度,如果我们使数据点非常小并且几乎完全透明,我们会得到什么?
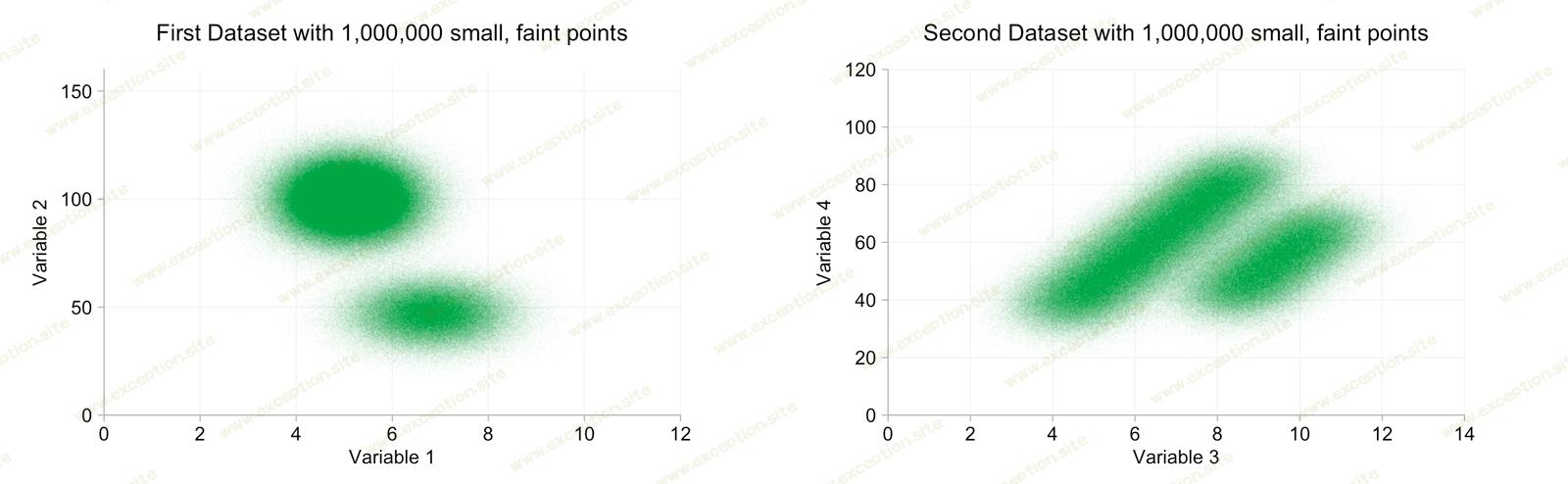
我们现在可以清楚地区分每个数据集中的两个集群。但是很难弄清楚任何细节。
由于我们无论如何都丢失了细节,因此似乎很容易质疑我们是否真的想要绘制一百万个数据点。在某些情况下,它可能会非常缓慢且不可能。二维直方图是另一种选择。通过对数据进行分箱,我们可以减少要绘制的点数,如果我们选择合适的色标,则可以挑选出散点图混乱中丢失的一些特征。经过一些实验后,我选择了从黑色到绿色再到高端白色的色标。请注意,这(几乎)与上面散点图中过度绘制所产生的效果相反。

在两个二维直方图中,我们可以清楚地看到两个不同的聚类代表从中提取数据的两个分布。在第一种情况下,我们还可以看到左上角的集群比右下角的集群有更多的计数,这一细节在具有一百万个数据点的散点图中丢失了(但从边际分布中更明显)。相反,在第二个数据集的情况下,我们可以看到两个集群的“高度”大致相当。
3d 图表被过度使用,但在这里(见下文)我认为它们在提供数据集中和不集中的广泛画面方面实际上工作得很好。特征 遮挡 是 3d 图表的一个问题,因此如果您在探索自己的数据时要走这条路,我强烈建议您使用允许通过旋转和缩放进行用户交互的软件。
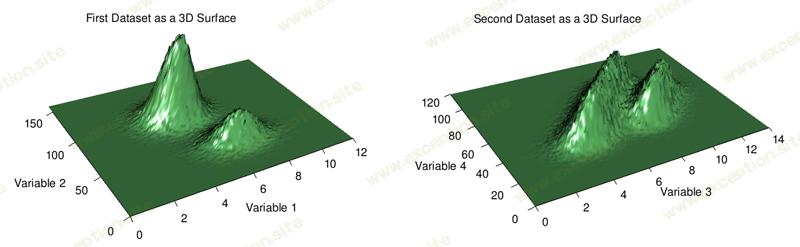
总之,散点图是一种简单且通常有效的可视化双变量数据的方法。但是,如果您的图表过度绘制,请尝试减小点大小和不透明度。如果做不到这一点,2d 直方图甚至 3d 曲面图可能会有所帮助。在后一种情况下要小心遮挡。