 异常教程
异常教程
参数化测试和理论
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
在这个关于使用 JUnit 进行单元测试的系列中,我们学习了几个单元测试方面以及如何使用 JUnit 实现它们。到目前为止,我们可以将这个系列总结为:
在这篇文章中,我们将了解参数化测试和理论。
JUnit 参数化测试
在测试时,通常会执行一系列仅输入值和预期结果不同的测试。例如,如果您正在测试验证电子邮件 ID 的方法,则应使用不同的电子邮件 ID 格式对其进行测试,以检查验证是否正确完成。但是单独测试每个电子邮件 ID 格式,将导致重复或样板代码。最好将电子邮件 ID 测试抽象为单个测试方法,并为其提供所有输入值和预期结果的列表。 JUnit 通过参数化测试支持此功能。
要了解参数化测试的工作原理,我们将从一个包含两个方法的类开始,我们将对其进行测试。
EmailIdUtility.java
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
上面的
EmailIdUtility
类有两个实用方法。
createEmailID()
方法接受两个
String
参数并生成特定格式的电子邮件 ID。格式很简单——如果将
mark
和
doe
作为参数传递给此方法,它会返回
mark.doe@testdomain.com
。第二个
isValid()
方法接受电子邮件 ID 作为
String
,使用
正则表达式
验证其格式,并返回验证结果。
我们将首先使用参数化测试来测试
isValid()
方法。 JUnit 使用特殊的运行程序
Parameterized
运行参数化测试,我们需要使用
@RuntWith
注释声明它。在参数化测试类中,我们声明与测试输入和输出数量相对应的实例变量。由于被测
isValid()
方法采用单个
String
参数并返回一个
boolean
,因此我们声明了两个相应的变量。对于参数化测试,我们需要提供一个构造函数来初始化变量。
EmailIdValidatorTest.class
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
我们还需要提供一个带有
@Parameters
注解的公共静态方法。测试运行器将使用此方法将数据提供给我们的测试。
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
上面的
@Parameters
注释方法返回测试数据元素的集合(这些元素又存储在数组中)。测试数据元素是数据的不同变体,包括测试所需的输入和预期输出。每个数组中测试数据元素的数量必须与我们在构造函数中声明的参数数量相同。
当测试运行时,runner 为每组参数实例化一次测试类,将参数传递给我们编写的构造函数。然后构造函数初始化我们声明的实例变量。
请注意我们在
@Parameters
注释中编写的可选
name
属性,用于标识测试运行中使用的参数。此属性包含在运行时替换的占位符。
- {index} : 当前参数索引,从0开始。
- {0}、{1}、… :第一个、第二个等等参数值。例如,对于参数 {“mary@testdomain.com”, true} ,则 {0} = mary@testdomain.com 和 {1} = true 。
最后,我们编写带有
@Test
注解的测试方法。参数化测试的完整代码是这样的。
EmailIdValidatorTest.java
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
在 IntelliJ 中运行参数化测试的输出是这样的。
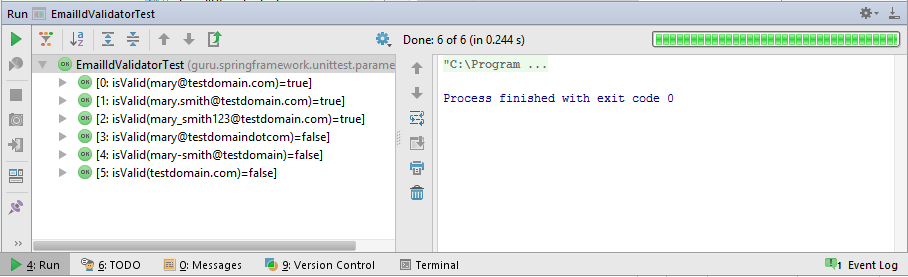
JUnit理论
在参数化测试中,测试数据元素是静态定义的,作为程序员,您负责确定特定范围的测试需要哪些数据。有时,您可能希望使测试更加通用。比如说,您可能需要测试一些更广泛的可接受输入值,而不是测试特定值。对于这种情况,JUnit 提供了理论。
理论是一种特殊的 JUnit 运行器 (
Theories
) 执行的特殊测试方法。要使用运行器,请使用
@RunWith(Theories.class)
注释对您的测试类进行注释。
理论
运行器针对称为
数据点
的多个数据输入执行理论。理论用
@Theory
注释,但与普通的
@Test
方法不同,
@Theory
方法具有参数。为了用值填充这些参数,
理论
运行器使用具有
相同类型
的数据点的值。
有两种类型的数据点。您可以通过以下两个注释使用它们:
- @DataPoint :将字段或方法注释为单个数据点。字段的值或方法返回的值将用作具有 相同类型 的理论的潜在参数。
- @DataPoints :将数组或可迭代类型的字段或方法注释为完整的数据点数组。 array 或 iterable 中的值将用作具有 相同类型 的理论的潜在参数。使用此注释可避免单个数据点字段使您的代码混乱。
注意 :所有数据点字段和方法都必须声明为 public 和 static 。
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
在上面的代码示例中,我们使用
@DataPoint
注释注释了一个
String
字段,并使用
@DataPoints
注释返回一个
String[]
names()
方法。
创建 JUnit 理论
回想一下我们之前在这篇文章中写的 createEmailID() 方法——“ createEmailID() 方法接受两个字符串参数并生成特定格式的电子邮件 ID。 ” 我们可以建立的测试理论是“ 如果传递给 createEmailID() 的 stringA 和 stringB 不为空,它将返回包含 stringA 和 stringB 的电子邮件 ID ”。这就是我们如何表示该理论。
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
我们编写的
testCreateEmailID()
理论接受两个
String
参数。在运行时,
Theories
runner 将调用
testCreateEmailID()
传递我们定义的
String
类型的数据点的所有可能组合。例如 (
mary,mary
)、(
mary,first
)、(
mary,second
) 等。
假设
理论对某些情况 无效 是很常见的。您可以使用假设将这些从测试中排除,这基本上意味着“ 如果这些条件不适用,请不要运行此测试 ”。在我们的理论中,假设传递给被测 createEmailID() 方法的参数 是非空值 。
如果假设失败,数据点将被忽略。以编程方式,我们通过
Assume
类的众多方法之一将假设添加到理论中。
这是我们带有假设的修改后的理论。
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
在上面的代码中,我们使用了
assumeNotNull
,因为我们假设传递给
createEmailID()
的参数
是非空
值。因此,即使存在
空
数据点并且测试运行器将其传递给我们的理论,假设也会失败并且数据点将被忽略。
我们一起编写的两个
assumeThat
执行与
assumeNotNull
完全相同的功能。我包含它们只是为了演示
assumeThat
的用法,您可以看到它与我们在之前的帖子中介绍的
assertThat
非常相似。
以下是使用理论测试 createEmailID() 方法的完整代码。
EmailIDCreatorTest.java
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
在上面的测试类中,我将
null
作为数据点包含在第 23 行的返回语句中,用于我们的假设和几个
System.out.println()
语句来跟踪参数在运行时如何传递给理论。
这是 IntelliJ 中测试的输出:
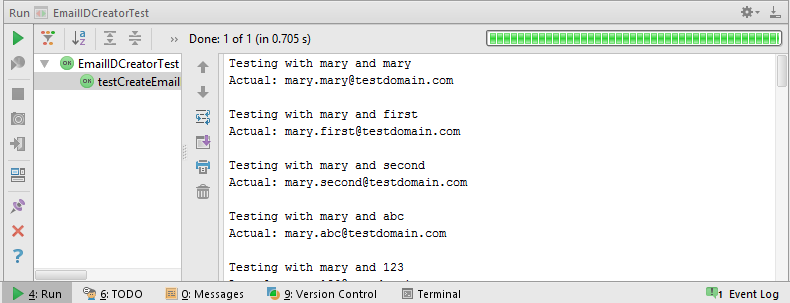
此外,这是我在使用 Maven 运行测试时得到的输出,供您查看:
package guru.springframework.unittest.parameterized;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class EmailIdUtility {
public static String createEmailID(String firstPart,String secondPart){
String generatedId = firstPart+"."+secondPart+"@testdomain.com";
return generatedId;
}
public static boolean isValid(String email){
String regex = "^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$";
Pattern pattern = Pattern.compile(regex);
Matcher m = pattern.matcher(email);
return m.matches();
}
}
在上面的输出中,请注意,无论何时将 空 值传递给 theory, assumeNotNull 之后的 theory 的其余部分都不会执行。
概括
JUnit 中的参数化测试有助于删除样板测试代码,并在编写测试代码时节省时间。这在使用 Spring 框架进行 企业应用程序开发 期间特别有用。然而,一个常见的抱怨是,当参数化测试失败时,很难看到导致它失败的参数。通过正确命名 @Parameters 注释和现代 IDE 提供的强大单元测试支持,此类抱怨很快就站不住脚了。尽管理论不太常用,但它们是任何程序员测试工具包中的强大工具。理论不仅使您的测试更具表现力,而且您将看到您的测试数据如何变得更加独立于您正在测试的代码。这将提高您的代码质量,因为您更有可能遇到您以前可能忽略的边缘情况。