 异常教程
异常教程
数据科学漫游癖:用蛋白质序列分析全球健康
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
十五年前,我有一个独特的机会在海上度过一个学期,这是一次乘坐改装游轮的环球旅行,结合了大学课程在四大洲九个国家的停留。这次一生一次的旅行让我产生了强烈的旅行癖和回馈国际社会的强烈愿望。
每一段旅程都始于足下
快进到几个月前,当时我加入了 exaptive 一个令人兴奋的新项目。一家大型非政府组织邀请我们分析各国的大量历史数据。目标:开发一种比“发达”和“发展中”的过时粗暴方法更好、更精细的国家分组方法。这个庞大、复杂、混乱的数据集和棘手的问题非常适合我在人工智能和数据科学方面的背景。
我的首要任务是组织和清理原始指标。任何曾经这样做过的人都知道,从 30,000 英尺的高空观察数据,如战争或政治,总是比在战壕中看起来更整洁。我从不责怪组织;这就是现实。国家有不同的名称和缩写。他们可以通过和平合并或血腥政变。即使是一些简单的事情,比如数据是由美国还是欧盟机构收集的,也会对数据处理造成严重破坏。
我开发了一系列 python 脚本,将指标折叠到正确的国家/地区,处理丢失或格式不正确的数据,并“旋转”指标,每个指标作为一个文件生成,因此生成的数据集按国家/地区及其组成部分组织指标。结果是一个 json 文件(迅速取代 xml 作为数据交换的黄金标准),可以进行进一步处理。
在旷野寻找
接下来发生的事情可以最好地描述为旅行癖的数字版本。似乎我的世界旅行带来的渴望也有利于我作为数据科学家的角色。准备好数据后,我开始探索像这样比较和分组时间序列数据的方法。我开始在音频领域进行搜索,寻找分析和分类音乐的算法。这似乎不太合适,因为音频信号在本质上往往更加混乱和周期性。音频处理算法可能会矫枉过正。
然后我偶然发现了一个有趣的算法,符号聚合近似 (sax)。 (有一个更高版本的算法称为 hot sax。谁说科学家不能有幽默感?) sax 将时间序列转换为字母序列,为使用字符串的标准数据挖掘技术打开了大门。在我的职业生涯早期曾处理过生物数据和文本,这引起了我的共鸣。我和团队讨论过,我们决定走这条路。
本着快速迭代的精神,我快速构建了一个用于获取输入并返回 json 结果的 web api 原型,集成了一个名为 jmotif 的开源库,它实现了 sax 算法,并在亚马逊 web 服务上建立了一个 api 实例。这在一周的时间里花费了大约十个小时的工作,这既是一项令人印象深刻的壮举,也是技术进步的证明。
意外的转折
当我们第一次以 sax 字符串形式查看国家/地区指标时,我们注意到这些字符串看起来很像 dna 序列。是否可以在这些字符串上使用聚类算法,就像遗传学家分析和比较 dna 链一样?我们开始讨论可能的聚类算法以及如何计算两个国家的相似度。
为了证明这一概念,我随后扩充了 Web API,以使用基本的聚类算法(k 均值聚类)和字符串距离函数 (levenshtein) 对数据进行聚类。然后,我通过对各个指标进行聚类来扩展概念,以创建每个国家/地区的矢量“指纹”。然后可以使用这些来进一步对国家进行聚类和分析。
结果令人震惊。再过一个星期后,我开发了这个,并将其集成到 expative 平台中,我们有了一个可以运行的应用程序,可以接收国家数据并在地图中呈现集群:
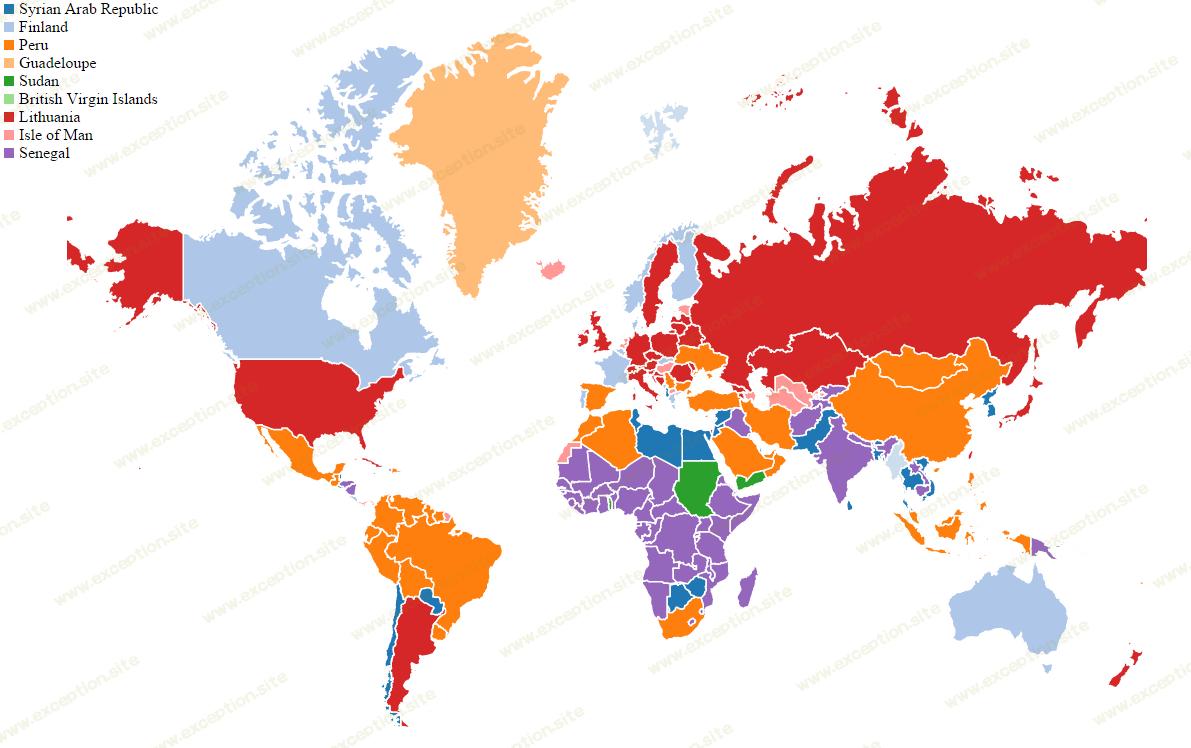
即使有了这些初步结果,我们也立即看到了一些有趣的模式。 (多么酷啊?)
两个陌生人的偶然相遇
由于我们将萨克斯管弦视为 dna,因此我们邀请了一位杰出的细胞生物学家加入对话。他指出,这些字符串看起来更像是蛋白质序列,而不是 DNA。我调整了算法以使用像氨基酸这样的 20 个字符的字母表,并从我们的时间序列数据中增加了幅度来模拟基因表达(产生的蛋白质的量)。添加这些元素后,我们立即看到了改进。
然后他建议我们尝试蛋白质比对的黄金标准,clustal omega 算法。想一想。我们从感觉很像音频信号或金融数据的地缘政治时间序列数据开始,最后我们与一位科学家讨论了蛋白质序列聚类。这是最好的认知扩展和数字旅行癖。
我再次更新了基于网络的 api,将 sax 字符串转换为蛋白质序列,并集成了 clustal omega 算法。我还在输出中添加了统计信息,因此我们可以评估针对不同算法和其他参数返回的聚类的质量。
意外发现
当我们完成分析并研究数据时,我们发现蛋白质比对的表现比我们之前的方法差一点,这表明事件发生的时间在分组国家中起着重要作用。我们还找到了理想的簇大小以进行进一步分析。
我想看看我们是否只是在拾取没有实际意义的虚假相关性,或者我们是否在做某事。我选择了其中一个指标,即营养不良,以查看特定集群中的国家是否显示出相似的营养不良水平和趋势。结果令人吃惊。单独的集群准确地捕获了水平较低且稳定的国家、水平适中但显着改善的国家,以及营养不良是真正问题的国家。我什至能够将教育、医疗保健和基础设施等特定政策决定与营养不良趋势联系起来。
一个晚上休息的地方
我们向非政府组织展示了我们的初步发现,他们显然很兴奋。我们有一些初步数据来支持他们的假设,即国家不应按地理或经济状况分组,而应按对关键指标(如识字率、国内生产总值、二氧化碳排放量、婴儿死亡率和数百个其他数据点)的深入、细致的理解进行分组。而且,我们在极短的时间内交付了结果。我们也很兴奋。通过回馈国际社会,我们能够立即产生积极影响。而且,我们现在拥有以新颖方式分析各种其他时间序列数据的工具。我们还能帮助谁,还有什么其他意想不到的事情在等着我们?这不是终点,而是再次流浪前的临时歇脚处。
完整的循环
在很短的时间内,我们(实际上,至少)跨越两大洲和六个城市寻找答案,在多个时区聘请了一个由四人组成的团队,并建立了一个我们希望能够产生影响的可行解决方案关于我们如何谈论国家和解决健康和贫困问题。
看来我的流浪癖毕竟还活着。当你放下先入为主的观念,让风和路带你去任何可能的地方时,伟大的事情就会发生。
 我为南非 khayelitsha hopolang 小学的学童拍摄的照片
我为南非 khayelitsha hopolang 小学的学童拍摄的照片