 异常教程
异常教程
选择重要的指标(CPU/磁盘/网络之外)
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
想象一下,您突然从普通的老开发人员晋升为高级架构师,并负责监督组织中所有工程团队的遥测工作。我最近在多伦多 DevOps Days 与一位经历过这种经历的人进行了交谈。他刚刚负责研究如何稳定 68 个不同开发团队的工作 (!)。通过稳定,他的意思是修复他们的产品开始出现大量阻塞中断的不稳定行为。
他的团队都在处理一个单一的大型微服务架构的不同部分,该架构已经变得足够大,以至于每项服务的单独开发工作正在分散并变得孤立。众所周知,他是一位友善且才华横溢的工程师,曾单独为许多服务做出过贡献,因此公司决定对他进行“DevOps”,即将他从目前的团队中解雇,专注于使整个系统协同工作更好的。他很乐意提供帮助,但很难弄清楚如何开始。他知道他想获得一些数据,让他清楚地了解问题出在哪里,但他的问题是他应该具体衡量什么。
CPU、内存、网络和磁盘指标都不是好老师
关于选择好的指标的理论已经写了很多。例如,我之前写过, 好的指标测试系统假设 。我的意思是,当我们考虑我们构建的系统以及它们应该如何运行时(例如,这个队列应该每秒处理 50K 的写入,或者那个平衡器应该总是选择负载最少的工作者),好的指标证实了我们的有效假设,抹黑我们的判断错误,并向我们展示边缘案例。他们告诉我们我们构建的东西实际上是如何工作的。
按照这个标准,经典的 CPU/内存/网络三巨头充其量是平庸的。您可能对一个进程应该使用多少 RAM 或 CPU 有一个有意义的假设,如果您的假设在实践中没有得到证实,您可能会了解您的创建(或者更可能是底层解释器或操作系统或垃圾收集器)。但是,衡量特定数据库调用所用时间或计算工作线程或队列元素总数等指标的指标反映了一些假设,这些假设有助于更有意义地了解您关心的事情。
让我举一个例子。假设您构建了一个进程,您预计每个 1000 个数据库连接池将消耗 4% 的 CPU 和 400k RAM,但是运行您的进程的生产系统使用的 RAM 和 CPU 比您假设的要多一个数量级.您是否了解了有关您的进程的一些信息,或者您是否了解了有关运行您的进程的主机的一些信息? CPU 和内存利用率等指标的问题在于它们衡量的是系统,而不是您的进程。这些指标让您更多地了解操作系统和运行时开销,而不是让您了解您真正关心的是什么。
我如何从头开始选择有意义的指标
构建分布式系统与理解它不是一回事,经验丰富的工程师通常可以凭直觉判断运行它的团队对架构的理解程度。证据无处不在:我们测试代码的深度,我们监控服务的具体程度,我们得出容量计划的精确程度,甚至我们部署更改的可重复性。
新上任的建筑师问“我从哪里开始?”问题是一位经验丰富的工程师。他知道什么是好的指标,他知道他负责同步的团队并不了解他们构建的内容。他不需要理论讲座,也不会浪费时间要求团队确定他们的指标。他必须自己上钩;问题很简单,在哪里?
好吧,让我告诉你过去对我有用的东西。每当我负责一大堆搅动的软件时,我都不是我写的,我画了一张图,那张图不可避免地看起来像图 1。事实上,这是一个实际的我第一次被录用时画的图,并试图围绕 Librato 的微服务架构在实践中的工作原理进行思考。
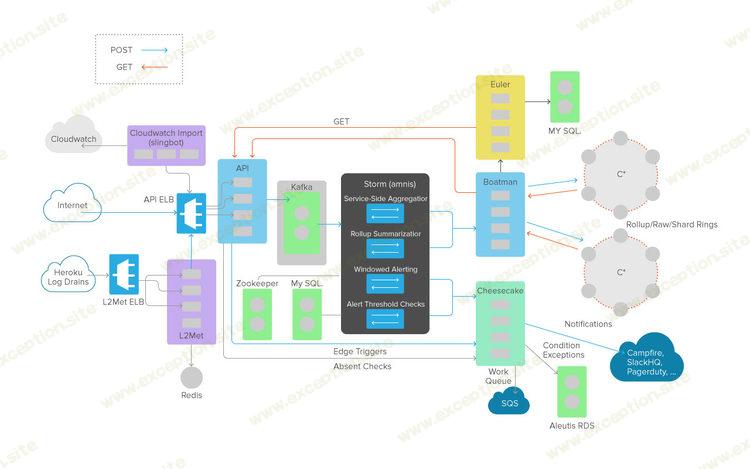
图1
第 1 步:测量服务之间的空间
通常,我们会将注意力集中在方框上,最后我们确实想知道这些服务中的每一个是如何工作的,这样我们就可以得出一些指标,这些指标是衡量它们在应该做的事情上表现如何的关键指标。然而,在这种情况下,我们将完全忽略这些框。事实上,我打算删除所有这些框标签,而是标记线条。在每一行上方,我将放置一个标签来标识每一行所代表的协议。这给了我们图 2。
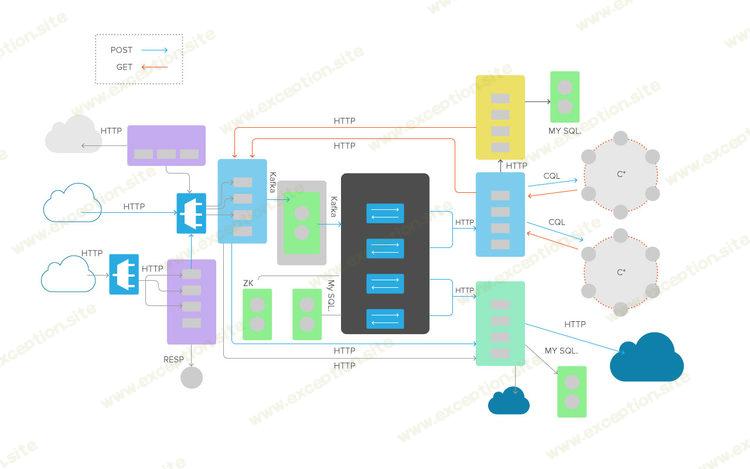
图 2
检查一下:我们以前难以理解的微服务架构只是变成了少数商品网络协议。我们构建的每个应用程序都是一个平衡方程;只要它处于平衡状态,它就会正常工作,最终我们会根除所有可能使它失灵的东西。但就目前而言,检测其何时失衡的最佳方法是对其组成部分之间的交互进行计时——测量服务之间的空间。我们的策略是找出一种方法来为每条线所代表的交互计时。
如果我让这听起来很容易,那就不是了。获取这些数字(我统称为服务间延迟数据)需要大量的工程知识。在几乎所有情况下,您都必须进入源代码并添加一些包装 API 或数据库调用的工具。有时您需要重新配置一组网络服务器或代理,每隔一段时间,您需要编写一些您自己的胶水代码或 API 包装器。
您应该以数十或数百毫秒的数量级结束。当应用程序出现问题时,这些数字将告诉您问题出在哪里(在哪个节点上的哪个服务中)。请注意,这与告诉您实际问题是什么不同,但我们会在一分钟内解决这个问题。
当然,您实际上需要将所有这些数据放在某个地方。这是我(和许多其他人) 详细写过的东西, 但在这里值得一提的是,您将需要一个可扩展的遥测系统来帮助您存储和分析所有这些东西。
第 2 步:从您的延迟数据中提取知识
当您启动并运行这些数字时,请仔细研究这些数字。注意基线值,并搜索行为模式和让您感到奇怪的事情。某些服务延迟会同时上升和下降吗?有些人看起来依赖于其他人吗?它们会随着一天中的时间或一周中的某天而变化吗?当您发现这些模式时,与运行这些服务的工程师交谈,看看这些模式是否证实了他们关于该服务应该如何工作的概念。您或其他人很快就会注意到数据中的某些内容,导致您说“嗯”之类的话。这是科学发现的声音。在运行它的工程师的帮助下深入研究该服务行为,您可能会遇到一两个有意义的指标。
当出现问题时,查看服务间延迟数据,看看您能多早发现问题。这些数字往往会在实际遇到问题的服务的上游变得很大。与运行这些服务的工程师共享您的数据,一起挖掘数字以找出问题所在,您可能会遇到一两个很好的指标。
第 3 步:重复
如果这听起来比安装一个神速的全自动 APM 更耗费人力和更慢,确实如此,但是果汁——以您收集的关于您的服务的洞察力和体现该知识的指标的形式——绝对值得一试。有效的指标需要关注和耐心。他们需要一些努力来识别,但每一个都是洞察力的体现;每个人都会教给您一些您所维护的服务所不知道的东西;每一件都是值得珍视、分享和谈论的东西。
在每个处理遥测数据的工程师的生活中,总有那么一刻你想停止摆弄监控工具,开始摆弄监控数据。如果您准备好将时间从管理指标基础架构转移到使用指标基础架构, 请立即注册免费试用 ,让我们帮助您识别和跟踪关键运营指标。